DeepSeek Distilled Models Compared: Performance vs. Efficiency
Explore the trade-offs between different distilled versions of DeepSeek models. We compare latency, cost efficiency, context handling, and best-fit scenarios for each version.
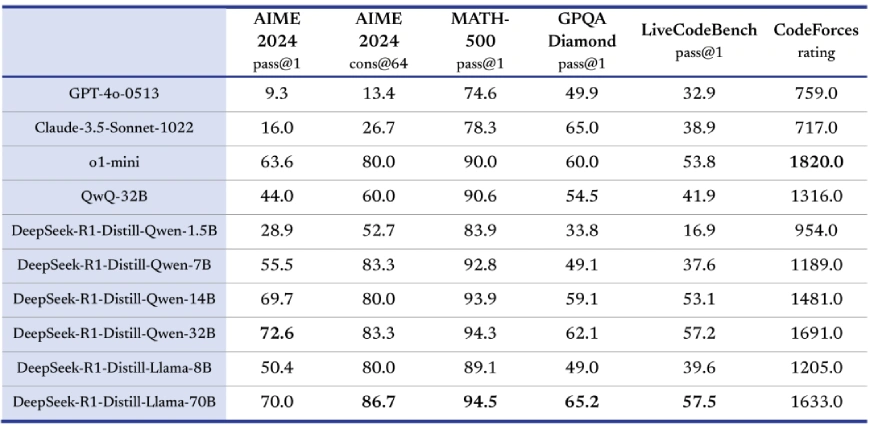
Understanding DeepSeek R1 Distilled Models
Large language models (LLMs) like DeepSeek R1 offer powerful capabilities, but their full-sized versions can be resource-intensive. To make them more accessible, developers often use distilled versions — smaller, faster models trained to mimic the behavior of larger ones. See how cost-saving breakthroughs in model training affect distillation.
DeepSeek R1 is available in multiple distilled variants, each optimized for different use cases:
| Model Variant | Parameters | Speed | Cost (GPU/hr) | Best Use Case |
|---|---|---|---|---|
| Qwen-32B (distilled) | 32B | Fast | Low | Chatbots, summaries |
| LLaMA 70B distilled version | 70B | Moderate | Medium | Coding, structured data |
These models maintain much of the performance of their full-size counterparts while being more deployable in real-world applications.
Qwen-32B: Lightweight and Fast
The Qwen-32B distilled model is a compact version that excels in low-latency environments. It's particularly suitable for:
- Real-time chat applications
- Short-form content generation
- Summarization tasks
Its smaller size means it runs efficiently even on modest hardware, reducing deployment costs. This makes it an excellent choice for startups or developers working within tight budgets.
Here's a sample API call using a distilled model:
import openai
client = openai.OpenAI(base_url="https://api.deepseek.com", api_key="your_api_key")
response = client.chat.completions.create(
model="deepseek-ai/Qwen-32B",
messages=[{"role": "user", "content": "Summarize this article in one sentence."}]
)
print(response.choices[0].message.content)
LLaMA 70B Distilled Version: Power with Balance
The LLaMA 70B distilled variant offers stronger reasoning and code-generation abilities than the 32B version. While slower and more expensive, it's better suited for:
- Multi-turn conversations requiring memory
- Code completion and debugging
- Structured data processing tasks
This model strikes a balance between performance and efficiency, making it ideal for mid-sized teams building production-grade AI tools. Compare DeepSeek Coder 7B to Gemini 1.5 Pro.
Choosing the Right Distilled Model
When deciding between the two:
- Use Qwen-32B if you need fast response times and lower compute costs.
- Choose the LLaMA 70B distilled version when accuracy and deeper reasoning are more critical than speed.
For more technical details and benchmark results, refer to the DeepSeek GitHub repository. See how DeepSeek compares to competitors.
